CASTtv has lots of recent and older tv shows online
ok guys, here we go again. i have some how confused the crap out of myself. i have made 2 apps so far, now all the sudden the xpath search is eluding me.
so here we go
I am using the xpath tool in firefox, and the firbug tool in firefox also.
but i cant seem to get the xpath to work in plex. i keep getting either syntax errors, or list is too large
User-Agent: Plex Firefox/2.0.0.11<br />
Host: localhost:32400<br />
Accept: */*<br />
Connection: keep-alive<br />
X-Plex-Language: en<br />
X-Plex-Version: 0.8.5-f4b13b5<br />
<br />
19:01:47.399786: com.plexapp.plugins.vbs : (Framework) Loaded en strings<br />
19:01:47.399911: com.plexapp.plugins.vbs : (Framework) Handling request : /video/CASTtv/:/function/VideoPage/KGRwMApTJ3RpdGxlVXJsJwpwMQpTJ2h0dHA6Ly93d3cuY2FzdHR2LmNvbS9zaG93cy90b3AtZ2VhcicKcDIKc1Mnc2VuZGVyJwpwMwpjY29weV9yZWcKX3JlY29uc3RydWN0b3IKcDQKKGNQTVMuT2JqZWN0cwpJdGVtSW5mb1JlY29yZApwNQpjX19idWlsdGluX18Kb2JqZWN0CnA2Ck50cDcKUnA4CihkcDkKUydpdGVtVGl0bGUnCnAxMApTJ1RvcCBHZWFyJwpwMTEKc1MndGl0bGUxJwpwMTIKUydTaG93cycKcDEzCnNTJ3RpdGxlMicKcDE0Ck5zUydhcnQnCnAxNQpOc2JzLg__<br />
19:01:47.409181: com.plexapp.plugins.vbs : (Framework) Calling named function 'VideoPage'<br />
19:01:47.506536: com.plexapp.plugins.vbs : (Framework) Received gzipped response from http://www.casttv.com/shows/top-gear<br />
19:01:47.531731: com.plexapp.plugins.vbs : (Framework) An exception happened:<br />
Traceback (most recent call last):<br />
File "/Users/sethreid70/Library/Application Support/Plex Media Server/Plug-ins/Framework.bundle/Contents/Resources/Versions/1/Python/PMS/Plugin.py", line 640, in __call<br />
return function(*args, **kwargs)<br />
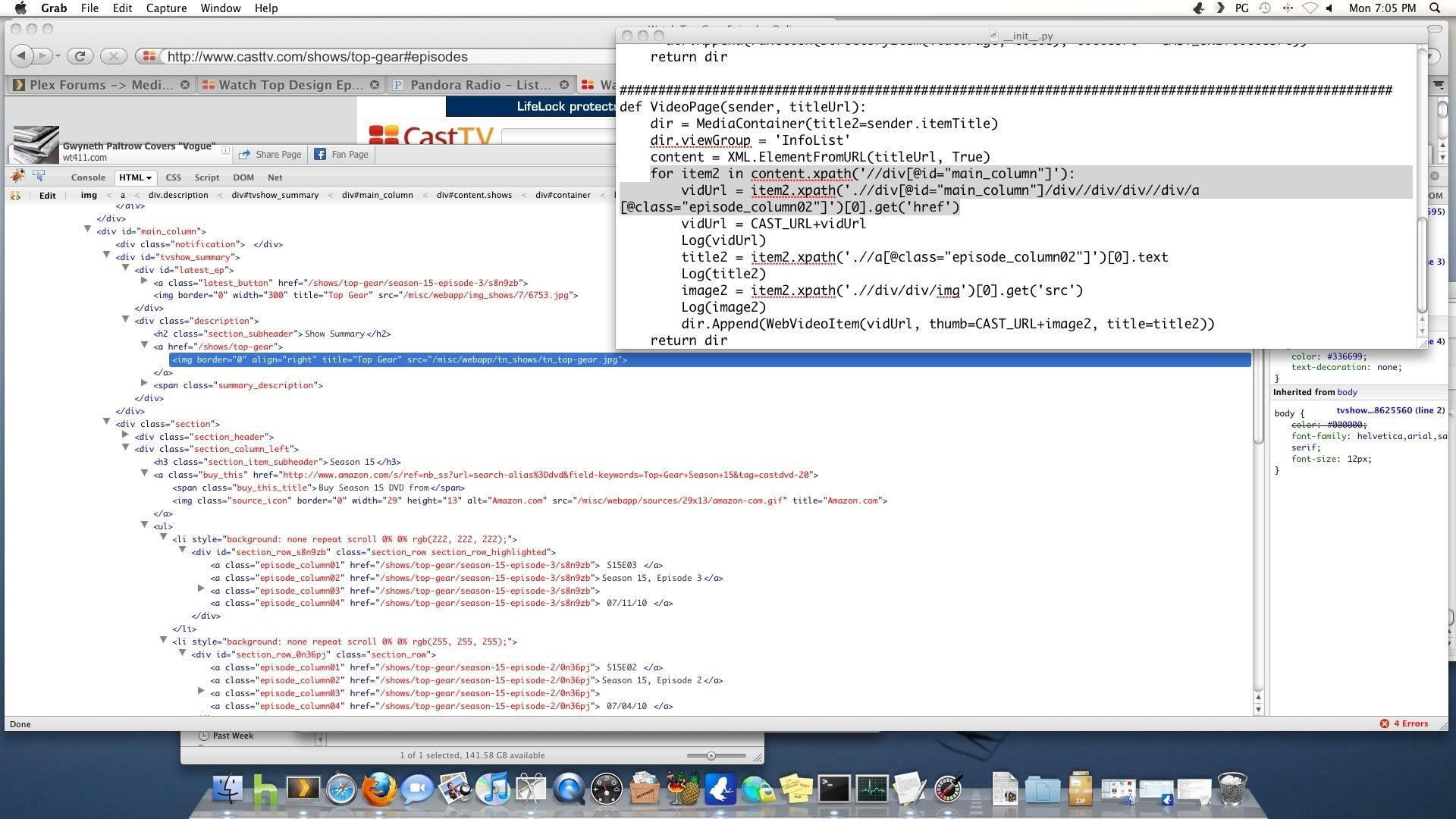
File "/Users/sethreid70/Library/Application Support/Plex Media Server/Plug-ins/CASTtv.bundle/Contents/Code/__init__.py", line 42, in VideoPage<br />
vidUrl = item2.xpath('.//div[@id="main_column"]/div//div/div//div/a[@class="episode_column02"]')[0].get('href')<br />
IndexError: list index out of range<br />
ok, can we go dumb for a second. like REAL dumb.
alright, thats the code im trying to get the data from. im missing something, i see the nodes. but i cant seem to graps how they are interacting.
so, be VERY CLEAR
// = search ALL of the xml ( in its first instance )????
//div/ = slash after node means i want you to look at the Div nodes DIRECT children?
so if we look at the picture i posted,
//div[@id="main_column"]/ = its now looking for the
with the id="main_column", then its looking at the DIRECT CHILD in that node for the next node
//div[@id="main_column"]/div = so like above, its finding the main column node. then looking for the DIRECT CHILD in that node for all other div's? or just the NEXT one?
//div[@id="main_column"]/div//div = so this one is then searching for a div node that is ANYWHERE in the node before it? 1 or all?
The leading ‘./’ says look under the item2 node in the tree. That itself was defined by ‘//div[@id=“main_column”]’ so you are looking for div tags with id=‘main_column’ as children of other div tags with id=‘main_column’. There aren’t any so the list is empty and you get index out of range.
To address you questions:
Not sure what you mean by in its first instance but yes, look anywhere in the xml tree
Trailing slash is not valid xpath. //div is valid and means look for div tags anywhere in the document tree.
Again, not valid with the slash but without it finds all div tags with the id attribute equal to 'main_column'.
This will return ALL div nodes that are direct children of div nodes with id attribute equal to 'main_column'
Finds ALL div nodes anywhere in the tree under the nodes defined by //div[@id="main_column"]/div
and Dbl_A i read that. 5 times. didnt explain it enough for me.
the reaons why im calling things wrong in the loop is because i didnt know that was the loop.
when i first posted about making an app i explained that i know very little about this style of python scripting/ programming. so really, this is new to me.
so if you think i dont know about something, or am using it wrong. i probably am.
I didnt know the ./ and // were different in the front part of the string. i thought they all were that way.
also johnny the trailing slash wasnt to search anything it was to mean, you are putting something else there and that would be X child. it was for example purposes in this thread, but that seems to have not worked out.
now how do you set the image outside the loop when you have to use the loop to find the specific image for a specific show?
The plugins are written in Python which is a full programming language. Any constructs available in Python are available for plugins to use. This includes all the usual flow control constructs (loops, if then else, etc) as well as data structures (lists, maps, sets, etc). If you don’t know what I’m talking about here it could be a wise thing to take a step back, find a basic Python tutorial (or book) and learn some basics. You’ll be banging your head against unmovable walls if you don’t know the simple stuff, which your comment about not realizing you were in a loop make be believe.
To be clear. This construct
<br />
for item2 in content.xpath('//a[@class="episode_column02"]'):<br />
implies content.xpath('//a[@class="episode_column02"]') returns a collection/list and the construct is looping over that list using standard python loop constructs. Each element in the list (which are XML DOM elements) are then assigned to the item2 local loop variable, which you can then operate on in the body of the loop to extract out whatever data you need from that DOM element. Before you try and go any further you really need to understand what's happening here - it is the basis of all plugins.
dbl_a, sadly i want to use both, so you were semi right. but i think i took care of that. but im still stuck on the little image and how to filter it.
johnny
i think i understand some of what the code is doing right there. i just dont understand the structure completely.
like so.
for item2 content.xpath(…
content is a variable right? and the content.xpath statement means? that content should be found in the xpath procedding the . ?
from my understanding the loop is searching the XML for all related data to the variable we put in the ( ) section of the “loop” or xpath like i call it.
so when the “loop” finds the data, it then looks to the append statement to where it will be used.
basically its like CSS kind of.
the css style sheet for a webpage houses a bunch of terms, or acronyms. this makes it easier to give a section settings without having to type them completely out, and can be used over and over easily.
now the way the xpath is working is its finding the nodes, that have the info we want.
then we are designating the “loop” results to correspond with the variable we named it.
i.e.
something = item2.xpath(…)
so we are giving the “something” term the results from the “loop”. for the specific nodes we told it to search in.
this is my understanding so far. the only thing im having issues with it seems is understanding how to call the data in the xml…somehow it got more complicated from the VBS plugin to the mtv and cast plugin… strange.
Honestly, your reply still makes it seem like you are confused with very basic concepts. You keep talking about the loop searching, which it isn’t doing, it is simply looping over a list of objects. That list of objects results from an xpath search, or pattern matching, operation.
I’ll try again by breaking it down into more explicit steps:
uses a framework object (XML) to construct an python object representing the XML document/tree found at the end of the url (after converting it from html). The object is then assigned to the variable content.
executes the xpath method on the content object. The xpath method returns a list of python objects, each object in that list representing an XML node. The objects returned are those for nodes that match the given xpath predicate. The returned list is assigned to the nodeList variable.
<br />
for node in nodeList:<br />
is a simple python loop accessing all elements in the node list. Since each element in the list is itself an object representing XML tree, xpath methods can be called on these individual elements also.
ok thats starting to make more sense, thats what i was looking for as far as the explanation.
not sure if i want to continue on this site though.
upon further research, casttv.com is similar to plex. its “tunneling” streams through their player from other sites.
so im not sure if will even work correctly to “tunnel” it twice.
let alone the Top Gear episodes i found ( on of the reasons i was doing this ) were not very good quality.
hmmm
johnny -
without sounding dumber.
when i say “searching” i mean this
content.xpath('//a[@class="episode_column02"]')
the section in the ( ) is the location the xpath is "searching" or atleast thats what im calling it.
and i understand that python is scrapping the html source for the page and finding and returning the nodes that are called. im just having an issue finding how to filter it enough to get what i need.
more complicated html source seems to trick my brain, and make it hard for me to see the nodes, and where the children and parents are.
this is why a tutorial on how to do a plex aopp would be awesome. the best thing for me is to see the steps, and the interactions. what happens after you do this, what changes after you do this.
more often than not if i make a change, it breaks the app and i cant tell if anything was right or not.
oh well, i will keep plugging away, thanks for the help.
Yeah, when starting a new plugin seeing if I can access the media is the first thing I do. No point in going forward if that isn’t the case.
As for the scraping: maybe you should attempt a site with a cleaner layout - pure XML maybe via either a web service or an RSS feed. They are generally much easier to work with under xpath. But yes, you can consider the xpath a search - it is really a path language. You can consider XML as a tree of nodes and the xpath syntax describes paths through that tree starting at the root node. It will return all leaves it finds at the end of the tree path.
im using firebug to look at the code, and it indents very strangely so sometimes its hard to see where a node is closed or not. so that can limit the amount of data in that node im calling.
looking at the source now, im seeing that the main_column node closes after only a few lines. thats probably why that doesnt work.
so, im going to continue to try at this. so any help would be appriciated
"//" Best way to describe is from W3Schools... "Selects nodes in the document from the current node that match the selection no matter where they are."
is there anyway you guys could give me an IF else example
i just spent an hour searching the net and finding NOTHING that fits what i want.
if img/@src = /image/blah/blah.gif ( slow down, this isnt what i think will work, just giving an example )
Log(vidUrl)
else ? delete? remove? ignore?
every if statement i see just throws it out there, so its hard to see it in my code.
and i know im being patient, but part of me is frustrated as it feels as though im bothering everyone, the questions i ask are meet with links, or repeat answers that are not answering the question i asked. I understand its most likely my fault for saying the wrong terminology, but i post code just so everyone can see what i “think” im talking about. plopping my code into any plex will show the problems, so its not that im not “providing” enough info.
and really, the xpath documentation online is really rediculous. i remember having these same issues when programming php for my database.
no “detailed” info
syntax is very specific, but yet no one shows it. syntax’s can be combined i understand that. but who knows what can be combined and what cant? and how the structure should look? thats what gets me.
weres the starting point, there is none. everyone just shows code from the middle of the xml, or a snippet so generalized that you cant get any real info from it.