Sent you a PM.
I’m going to see what @Maximilious has with his machine then your machine is next
Sent you a PM.
I’m going to see what @Maximilious has with his machine then your machine is next
sorry to bother ChuckPa,
all Transcoder preview files like the qpkg you linked above are a 404 the last day or two
"errors" : [ {
"status" : 404,
"message" : "File not found."
} ]
}
Was mentioned a couple of times, but I didn’t want to bother folks there in case it’s user error ![]()
I am also running into this issue. This is a shared library issue with libdrm.so.2 included in the NVIDIA driver QNAP package which seems to be outdated.
I am running the linuxserver/plex docker image on a QNAP NAS with the 5.0.4.1 NVIDIA driver QNAP package (460.39). Since Plex 1.23 which changed the toolchain & loader to musl, I have set my LD_LIBRARY_PATH to /usr/local/nvidia/lib (equivalent to /opt/NVIDIA_GPU_DRV/lib on the host machine) in order to load the CUDA library necessary for the hardware transcoder. Up until the 1.29.1 release, I had no issue.
Based on my troubleshooting, it looks like that the Plex Media Server binary started, since the 1.29.1 release, calling the drmGetDevices2 function included in more recent libdrm.so.2 versions (>= 2.4.75). Unfortunately, this function isn’t supported by the library version included in the 5.0.4.1 NVIDIA driver QNAP package.
inside container (any version)
# readelf -a -W /usr/local/nvidia/lib/libdrm.so.2 | grep drmGetDevices
150: 0000000000008140 696 FUNC GLOBAL DEFAULT 12 drmGetDevices
# readelf -a -W /usr/lib/plexmediaserver/lib/libdrm.so.2 | grep drmGetDevices
0000000000013288 0000005b00000007 R_X86_64_JUMP_SLOT 000000000000ba84 drmGetDevices2 + 0
91: 000000000000ba84 353 FUNC GLOBAL DEFAULT 12 drmGetDevices2
238: 000000000000bbe5 20 FUNC GLOBAL DEFAULT 12 drmGetDevices
144: 000000000000ba84 353 FUNC GLOBAL DEFAULT 12 drmGetDevices2
145: 000000000000bbe5 20 FUNC GLOBAL DEFAULT 12 drmGetDevices
I was able to find a workaround changing my LD_LIBRARY_PATH to /usr/local/nvidia/nvidia.u18.04 which includes libcuda.so.1 but not libdrm.so.2 allowing the included shared library /usr/lib/plexmediaserver/lib/libdrm.so.2 to be loaded instead. Another way would have been to rename the library to avoid being loaded but may affect other GPU functionalities at the NAS host level.
inside container (1.29.0)
# ldd /usr/lib/plexmediaserver/Plex\ Media\ Server | grep libdrm.so.2
libdrm.so.2 => /usr/local/nvidia/lib/libdrm.so.2 (0x00007f8c09e00000)
inside container without workaround (1.29.1)
# ldd /usr/lib/plexmediaserver/Plex\ Media\ Server | grep libdrm.so.2
libdrm.so.2 => /usr/local/nvidia/lib/libdrm.so.2 (0x00007f4be9a00000)
inside container with workaround (1.29.1)
# ldd /usr/lib/plexmediaserver/Plex\ Media\ Server | grep libdrm.so.2
libdrm.so.2 => /usr/lib/plexmediaserver/lib/libdrm.so.2 (0x00007fe3e3ebd000)
@jesplex can you share your docker-compose file for the workaround?
So by setting LD_LIBRARY_PATH to /usr/local/nvidia/lib, that library folder was taking precedence over the one included with the Plex Media Server release, when it should actually only be used if a given library, such as CUDA is not included in the release.
This can be resolved by including the Plex Media Server release library folder in LD_LIBRARY_PATH.
version: '3'
services:
plex:
image: linuxserver/plex
container_name: plex
network_mode: host
restart: always
devices:
- /dev/nvidia0
- /dev/nvidiactl
- /dev/nvidia-uvm
volumes:
- ./data:/config
- /share/Multimedia:/data
- /dev/shm:/transcode
- /opt/NVIDIA_GPU_DRV/usr:/usr/local/nvidia:ro
environment:
LD_LIBRARY_PATH: /usr/lib/plexmediaserver/lib:/usr/local/nvidia/lib
PUID: <uid>
PGID: <gid>
TZ: <timezone>
VERSION: latest
The other option can be to append /usr/local/nvidia/lib at the end of /usr/lib/plexmediaserver/etc/ld-musl-x86_64.path inside the container. Doing so remove the need to define LD_LIBRARY_PATH.
To anyone missing the QKPG - here it is. ChuckPA worked with me last night and got me squared away.:
I found the updated kernel driver and re-installed my GPU driver on my QNAP and that resolved my video card resource issue. After that, Chuck removed my docker instance and we went back to the native app. He checked over his script and we saw hardware transcoding is working as intended!
Thanks again @ChuckPa!!
Don’t forget to remove /transcode as the transcoder temp directory setting
in Settings - Server - Transcoder - Show Advanced
Couple of things for anyone moving back to the native app:
that resolved the issue for me ![]()
Thanks
Now just need to find the 1.29.2 image ![]()
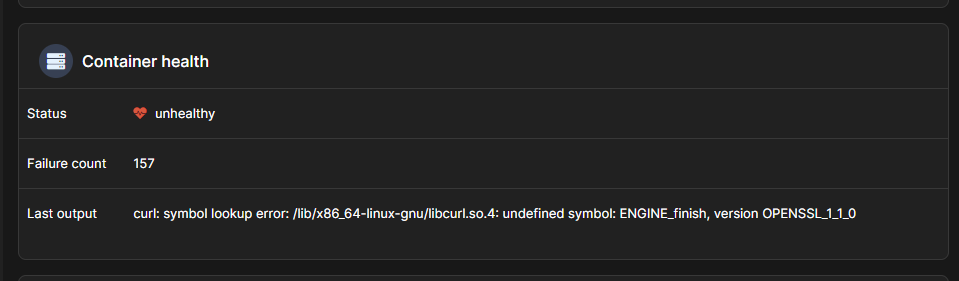
@jesplex - any idea for the below? Thanks ![]()
If the container reports unhealthy then the communication with the Docker engine (the core) isn’t working.
The libcurl.so.4 undefined symbol error is in your linux distro.
That’s a missing or bad update
Its to do with this line in the docker file:
LD_LIBRARY_PATH: /usr/lib/plexmediaserver/lib:/usr/local/nvidia/lib
I don’t know docker enough to understand that I need to add/change to get it to work. Switching to the linuxserver image, it doesn’t have a healthcheck, but I can create my own so thats a workaround for now.
If you’ve isolated it down to that statement, consider retaining the existing LD_LIBRARY_PATH.
LD_LIBRARY_PATH: /usr/lib/plexmediaserver/lib:/usr/local/nvidia/lib:"$LD_LIBRARY_PATH"
Are you dropping off something the container needs?
I have the same issue with official pms image, if I put this path for update to last pms docker
With that setting LD_LIBRARY_PATH to /usr/local/nvidia/lib
This error: curl: symbol lookup error: /lib/x86_64-linux-gnu/libcurl.so.4: undefined symbol: ENGINE_finish, version OPENSSL_1_1_0
@walderston @surinas1 It would be helpful if you could provide your actual docker compose template or docker command line that is generating the error.
If specifying LD_LIBRARY_PATH is an issue, you may want to consider the alternate solution I mentioned by updating /usr/lib/plexmediaserver/etc/ld-musl-x86_64.path part of the container.
/usr/local/lib
/usr/lib/x86_64-linux-gnu
/usr/local/lib/x86_64-linux-gnu
/lib/x86_64-linux-gnu
/usr/lib64
/usr/local/nvidia/lib
This is not achievable when specifying an environment variable either in the docker compose file or the docker command line. The only way to do so is by setting that variable through a script when the container starts.
you’re right. I forgot about ld-musl.
I looked back at the QNAP to confirm. I build the ld-musl path dynamically
Ok, for me this is my compose about pms-docker:1.28.2.6151-914ddd2b3 configuration that has been working without problems over last year, compose adapted from here: Guide_plex_hardware_transcode_with_docker_and_gpu
docker run -d \
--name="plex" \
-e VERSION=docker \
--network=dockernetwork \
-p 53426:32400 \
--restart=always \
-v /share:/share \
-v /share/tv:/tv \
-v /share/movies/:/movies \
-v /share/DockerVol/plex/config:/config \
-v /share/CACHEDEV1_DATA/.qpkg/NVIDIA_GPU_DRV/usr:/usr/local/nvidia:rw \
--device=/dev/nvidia0:/dev/nvidia0 \
--device=/dev/nvidiactl:/dev/nvidiactl \
--device=/dev/nvidia-uvm:/dev/nvidia-uvm \
-v /share/DockerVol/plex/Plex_Transcode:/transcode \
-e PATH="/usr/local/nvidia/bin:/usr/local/cuda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin" \
-e CUDA_VERSION="10.0.130" \
-e CUDA_PKG_VERSION="10-0=10.0.130-1" \
-e LD_LIBRARY_PATH="/usr/local/cuda/extras/CUPTI/lib64:/usr/local/nvidia/lib:/usr/local/nvidia/lib64" \
-e NVIDIA_VISIBLE_DEVICES="all" \
-e NVIDIA_DRIVER_CAPABILITIES="all" \
-e NVIDIA_REQUIRE_CUDA="cuda>=10.0 brand=tesla,driver>=384,driver<385 brand=tesla,driver>=410,driver<411" \
-e PLEX_UID=1020 \
-e PLEX_GID=1001 \
plexinc/pms-docker:1.28.2.6151-914ddd2b3
And this is my new test compose from latest plex [1.29.1.6316-f4cdfea9c] where the error explained by me and by @walderston occurs:
docker run -d \
--name="plex_test" \
-e VERSION=docker \
--network=dockernetwork \
-p 32400:32400 \
--restart=always \
-v /share:/share \
-v /share/tv:/tv \
-v /share/movies/:/movies \
-v /share/DockerVol/plex/_test/config:/config \
-v /share/DockerVol/plex/_test/Plex_Transcode:/transcode \
-v /share/CACHEDEV1_DATA/.qpkg/NVIDIA_GPU_DRV/usr:/usr/local/nvidia:rw \
--device=/dev/nvidia0:/dev/nvidia0 \
--device=/dev/nvidiactl:/dev/nvidiactl \
--device=/dev/nvidia-uvm:/dev/nvidia-uvm \
-e PATH="/usr/local/nvidia/bin:/usr/local/cuda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin" \
-e LD_LIBRARY_PATH="/usr/lib/plexmediaserver/lib:/usr/local/nvidia/lib" \
-e PLEX_UID=1002 \
-e PLEX_GID=1001 \
plexinc/pms-docker:latest
If you @jesplex could guide me by updating /usr/lib/plexmediaserver/etc/ld-musl-x86_64.path part of the container I could try to see if it solves it but I don’t know how to do it.
I know that I could go back to the option of continuing to use qnap’s qkpg but since you discovered docker it is better.
So the error is related to the container healthcheck which is failing to call curl. The PMS is actually unaffected.
Anyway the error is indeed related to LD_LIBRARY_PATH which is messing up some of the necessary standard librairies for curl. While you could just add /lib/x86_64-linux-gnu at the beginning of the environmental variable, I think updating /usr/lib/plexmediaserver/etc/ld-musl-x86_64.path is the best solution in the end.
To do so, you can create a file name ld-musl-x86_64.path in your Plex docker folder for example with the following data:
/usr/local/lib
/usr/lib/x86_64-linux-gnu
/usr/local/lib/x86_64-linux-gnu
/lib/x86_64-linux-gnu
/usr/lib64
/usr/local/nvidia/lib
And mount it as a volume:
docker run -d \
--name=plex \
--network=dockernetwork \
-p 32400:32400 \
--restart=always \
-v /share:/share \
-v /share/tv:/tv \
-v /share/movies/:/movies \
-v /share/DockerVol/plex/config:/config \
-v /share/DockerVol/plex/Plex_Transcode:/transcode \
-v /share/DockerVol/plex/ld-musl-x86_64.path:/usr/lib/plexmediaserver/etc/ld-musl-x86_64.path:ro \
-v /share/CACHEDEV1_DATA/.qpkg/NVIDIA_GPU_DRV/usr:/usr/local/nvidia:ro \
--device=/dev/nvidia0 \
--device=/dev/nvidiactl \
--device=/dev/nvidia-uvm \
-e PLEX_UID=1002 \
-e PLEX_GID=1001 \
plexinc/pms-docker:latest
Ok yes now yes, @jesplex Thanks a lot of, for explaining how to use ld-musl-x86_64.path , I have tried it from scratch, With a new test server, I activate Use hardware acceleration when available and I verify that now the transcoding from the gpu works again.
And the mentioned error no longer appears and the container does not remain in an unhealthy state (curl: symbol lookup error: /lib/x86_64-linux-gnu/libcurl.so.4: undefined symbol: ENGINE_finish, version OPENSSL_1_1_0) now it is ok.
I have noticed that the only detail when the container is started with respect to my old compose is that once the container is started and plex is started, this error appears “Jobs: Exec of ./CrashUploader failed. (2)”
[services.d] starting services
Starting Plex Media Server.
[services.d] done.
**Jobs: Exec of ./CrashUploader failed. (2)**
Critical: libusb_init failed
I am not sure about this one. This error shows even if the container is started with no option. This is specific to the plexinc/pms-docker image. I use the linuxserver/plex image and there is a message indicating that the libusb_init error can be ignored.
Starting Plex Media Server. . . (you can ignore the libusb_init error)