In case you’re not familiar with it, plex-meta-manager creates custom collections and poster overlays, and has a ton of different configuration options. If you get it up and running, I can provide you with my config file so you can see a bit of what I do with it, and maybe others can provide theirs (redacted) as well.
My understanding is that the DB Cache Size is simply an option to display the cache size that is set in Plex, so that it will display in the logs and makes it easier to troubleshoot issues.
Python is going away? I had no idea. Isn’t Tautulli also written in Python? Does that mean all these tools will stop working? I hope the developers are aware of this, since I haven’t heard any discussion about it. Do you know when the Python hooks will stop working?
My understanding is that PMM uses python-plexapi, which is another 3rd party tool which acts as a translation between Python and Plex’s cURL API endpoints. This isn’t being deprecated to the best of my knowledge.
The issue here is that for some reason the API endpoints used by python-plexapi (and in turn PMM) for updating Plex metadata have taken a performance nosedive in recent versions.
Yes, All of PMM’s communication with Plex happens via the PlexAPI python library linked by Departed69.
I’m curious what about the tool is considered “micromanaging”? It’s basically creating collections/playlists and setting artwork, both things that the UI supports, querying Plex for bits of information on the way and caching that stuff to avoid talking to Plex as much as possible. Is it the scale?
If you run this against a server running Version 1.29.2.6364, it returns an empty array.
Run against Version 1.32.7.7616, it returns a 500 Internal Server Error.
curl https://1.32.7.7616-plex-server/library/sections/18/all\?includeGuids\=1\&label\=DOES_NOT_EXIST\&X-Plex-Token\=BINGBANGBOING
<html><head><title>Internal Server Error</title></head><body><h1>500 Internal Server Error</h1></body></html>
That would be my understanding; nothing has changed but the version of Plex. 1.29 Plex says “here’s your empty result set”, while 1.32.7 Plex throws a 500 which to my mind is a regression.
What if you built the DB on a 1.29 Plex server and then take it through every upgrade of PMS until the current version and see if something went awry along the way?
At the end of the day, I’d love to have my PMS performance back again and half the db size would be great as well.
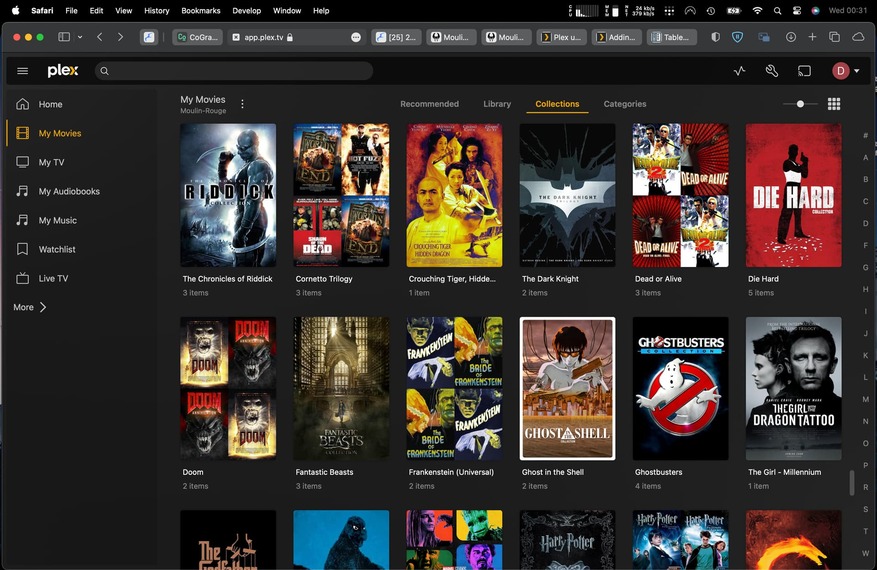
Plex does kind of have its own Plex meta manager that makes headings for a collection of tv or films BUT they only show under recommended and it’s all random. Perhaps theres some scope to build this into a proper function that users can customise.
Like just now I noticed its showing ‘Fright Night Features’ a collection of all my ‘scary’ movies.
I think WHY we use plex meta manager is it creates collections based on these groups of data plus a load more.
It was pointed out in an earlier post that there were more efficient ways to perform multi-item edits and that the specific tool mentioned was not using them. A follow-up post by the developer of Tautulli provided a link to the specific changes in python-plexapi to accommodate these changes. Was there a follow-up from the developer acknowledging this and stating that they would use the updated API?
Thanks for the positive note. The dev for PMM has mentioned that it’s on the roadmap. So batch edits is the way to go.
I think that what we are trying to point out is that we were hammering the 1.29 version equally and it was fine. Was it optimal…no. From a testing perspective, we saw a general and significant performance degradation when moving off of 1.29 with 1.32.7.* having the most performance degradation and issues. 1.31.2.6810 seems to be the last “decent” version post 1.29 however still has degraded since1.29.