For those that don’t want to wait, don’t follow these instructions. There are much faster instructions upstream in the thread, though I would encourage anybody who isn’t critically low on space to just wait.
This isn’t even wrong.
For those that don’t want to wait, don’t follow these instructions. There are much faster instructions upstream in the thread, though I would encourage anybody who isn’t critically low on space to just wait.
This isn’t even wrong.
24hrs and counting over here.
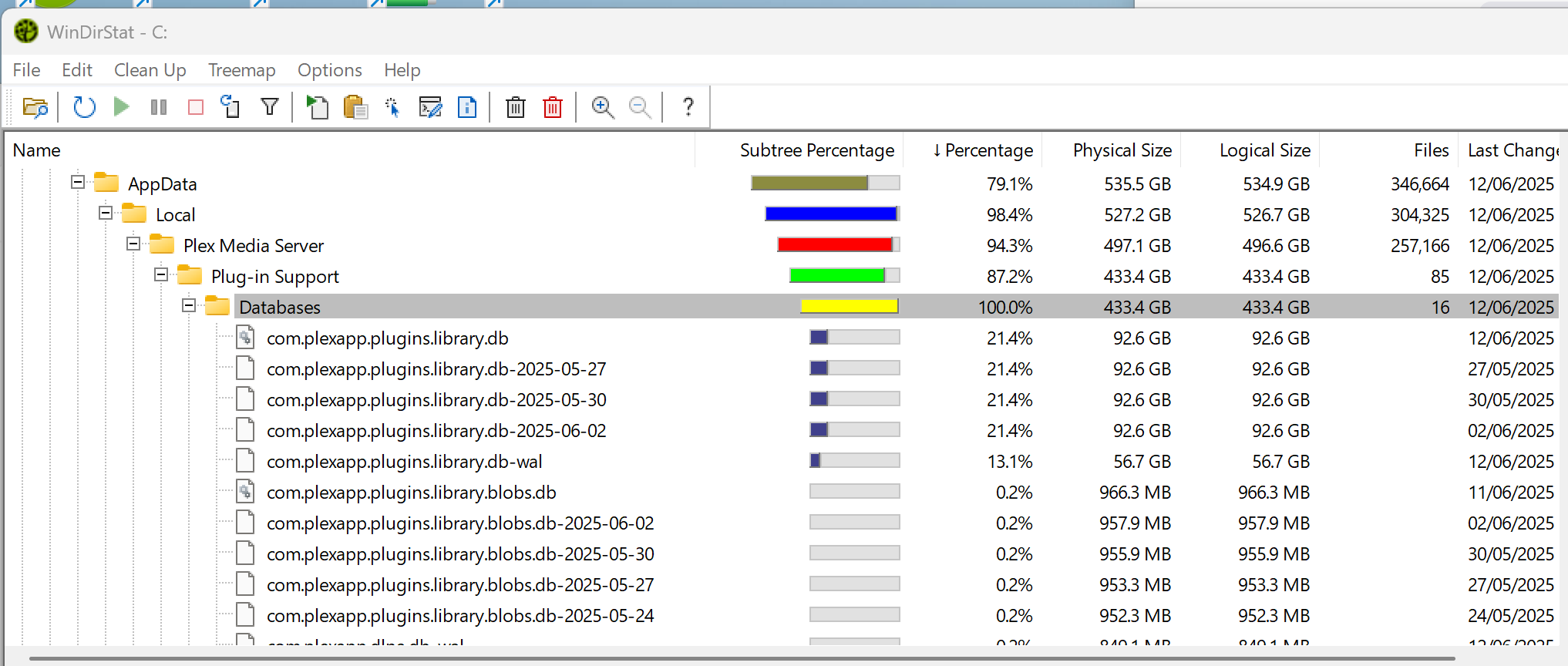
looks like my DB has grown more than i can clear out to have enough space for this. Not in a position to upgrade the drive currently. Is my only solution to restore a backup? Seems I have 3 backups but they are so small deleting them wont make a difference for this process.
My Plex DB is currently 92GB, and with the three backups and the wal file they’re taking up over 430GB on my hard disk, which now has only 37GB free!
My Plex server keeps crashing when I try to run optimise or any changes. Can I just delete the three backups, or is it not that straight forward?
It’s killing my setup, Plex keeps going down and my PC is currently being affected by it hogging so much space.
I am already on Version 1.41.8.9834 and it’s not resolving itself, and when I use the WebTools to initiate an optimise I can’t see that it’s doing anything other than hanging and crashing my Plex Server.
Running a DELETE statement is going to be tediously slow if your database has grown really really big.
The fixup in 1.41.8 creates a new temporary table, copies the good rows from the old table and then drops the old table entirely. This is much faster than doing delete operations but still will take a bit especially during the vacuum.
If you want to trigger this process manually (and not wait for the weekly scheduled task) you can call the following request:
POST http://localhost:32400/butler/OptimizeDatabase?X-Plex-Token=:yourtoken
Curl command:
curl -X POST \
'http://localhost:32400/butler/OptimizeDatabase?X-Plex-Token=:yourtoken' \
This assumes you’re running the command on the same machine as PMS is running, otherwise replace the http://localhost part.
Apologies for being annoying, but I am 36 hours and counting on my DB “optimizing." Anyone had it take this long? The wal file is growing, but at an incredibly slow pace… now up to 48.5gb (from 33gb when I first started checking some 16hrs ago) on a DB file that is 146gb… Is it worth just letting it go for, at this point, which will likely be a few more days? Any thoughts?
You could process the db files on a different system, then move them back to your “real” server. The OS does not have to be the same. For example, you could run PMS on Linux and use PMS on Windows to de-bloat the db file.
PMS1 = current server; PMS2 = new/different server for processing db files
Install & claim PMS 1.41.8.9834 on a different system, PMS2. Do not create any libraries. In Settings → Libraries, disable Empty trash automatically after every scan.
Stop PMS on both systems.
On PMS2, delete the existing (empty) db files.
Copy com.plexapp.plugins.library.db and com.plexapp.plugins.library.blobs.db from PMS1 to PMS2.
Start PMS2.
Using WebTools-NG or POST/curl listed by @drzoidberg33 (two posts above), initiate a Database Optimization on PMS2.
Hum the Jeopardy theme song while you wait for the process to complete.
When finished, stop PMS2 (and PMS1 if still running).
On PMS1, rename com.plexapp.plugins.library.db and com.plexapp.plugins.library.blobs.db to .bak/.save (or just delete them if you’ve a copy elsewhere).
On PMS1, delete any -shm and -wal files (they normally go away when PMS is stopped).
Copy com.plexapp.plugins.library.db and com.plexapp.plugins.library.blobs.db from PMS2 to PMS1.
Start PMS1.
Try rebooting the plex server.
I had a similar issue. I tried the DELETE query, I tried the method of moving to a temp table, and then dropping the bloated table, I tried DBRepair, everything would just run for hours.
I rebooted the plex server, and tried the moving to temp and dropping again, and to do all the steps was under 20 min. DB went from 77GB to 200mb
Just had a thought. All I care about in my DB is my watch status. Has anyone thought about using something like this: GitHub - cetteup/transfer-plex-user-viewstate: Transfer Plex viewstate information (watched/unwatched, view progress and ratings) between users to extract that for a “fresh” install? Any downsides I am not thinking of?
These ones.
You copy the non null values to a temp table, then drop the bloated table and rename the temp table.
Or just try the delete and vacuum like you were doing. I dunno I just know mine would do the same thing, move quickly, come to a halt and just hang.
So I rebooted and then did those steps above, but delete and vacuum might work as well.
Same steps used by Plex Media Server.
Using DELETE FROM statistics_bandwidth WHERE account_id is NULL; will be much, much slower.
Running this seems to start off the optimization OK, but then within a few minutes locks up the server again/becomes inaccessible like the normal scheduled tasks were doing before and I have to restart it. I’m definitely running 1.41.8.
My database is huge, 42GB.
Looking at the logs, the optimization seems to get to 60% within a couple of minutes, before starting to hang then the server becomes unresponsive and it doesn’t get any further - no more logs about optimization follow. Obviously no change in DB size in only a few mins til it all locks up!
The server will be non responsive during the process.
The db size will not change until the end.
It will take hours to complete.
Let it run.
Is there anything that will indicate it’s still actually making any progress once it’s unresponsive? Like logs or temp files? As it seems to be doing nothing. The wal file is not growing past an initial 9.18mb - I can wait but it just doesn’t look like it’s making any progress and stalled out. Thanks
Not that I noticed. The log files on my server had a lot of warnings about the system being non-responsive to clients and long database query times, but that is to be expected.
Plex Media Server will be running. At some point the -wal file will start growing. It will grow to the size of the bloated database.
When complete, the database will be normal sized, the system will be responsive, and you’ll see a log message that the optimization progress is 100%.
The process did not slam the CPU. Initially there was minimal drive activity. Once the -wal file was growing the drive activity greatly increased.
If your server has a low power CPU or the database is on a hard drive then it could take a very long time.
72 hrs and counting… this is insanity. At this rate I probably have a few more days… I am going to just try and get a backup working. I also have my MPB working on optimizing the DBs which is still slow going, but a it faster.
Thank you! My db was 133 GB and now it’s 229 MB. The whole process took less than an hour.
Edit: By the way, I’m running Version 1.41.8.9834, so whatever fix was supposed to happen in 1.41.8 did not work for me.
Yep 48 hours and counting here…I’d kill for the ability to run the process on a faster machine then copy the database over to the low power server. 192GB db
EDIT: I was reminded that it may be necessary to check ownership & permissions when moving the db between systems.
For example, if PMS is running on a Linux system and you use Windows to repair the db, the files may have different ownership & permissions when moved back to the Linux host.
On Linux, the default owner:group is plex:plex. Default file permissions are 644.
My apologies for the extreme delay on follow up!
To answer your question:
I did clear out 3 of the 4 .db and .blob.db backups files prior to using the ‘Optimize Database’ function in WebTools-NG to create as much space a possible since my .db and all the .db backups were at 33.7GB each.