Server Version#: 4.149.0
Player Version#: Sony Bravo TV App
Lifetime Plex Pass
Setup
ProxMox Hypervisor
Ubuntu Server 22.0.4LTS
i7 11th gen iGPU
10Gbps Network
12 cores/16GB RAM/200GB Storage with about 30GB free
Synology NAS Running latest code
SMB mapped network drive on Plex Server to Synology Media store
This just started within the last 1-2 months, setup has been working fine for years without this issue. Randomly while watching a show locally or remotely, plex will suddenly stop playing with a message “Your connection to the server is not fast enough to play the media” and it will just buffer and not resume play. If I back out of the media, my plex server is still up and still lists all the media I have on it, however I am unable to play any content. When I try to play different shows or movies, it just shows the buffering icon and never plays. When this happens, if I log into the Plex server and go to my mounted folder and try to list the contents, it will just hang. Using different devices like Phone, PC to watch plex does not work and neither does remote streaming. When this does happen, the SMB file share for the media works fine from my desktop PC and there are no other issues access or utilizing the NAS. This seems to happen regardless of transcoding and happens to all media and what appears to be random. After about 15 minutes, everything works fine again until it happens again. Which could be in 15 minutes or 4 hours.
Others I have spoken to who have the same issue have reported the following
NFS or SMB doesnt make a difference
Network hardware does not appear to be a problem
Happens on Windows or Linux
I am an experienced network engineer and my home network is more robust and well built that most data centers.
Further investigating, I did swap to using NFS and this had no impact on the issue at all. I am sure its not a network issue at this time and also I am sure its not an OS issue as well.
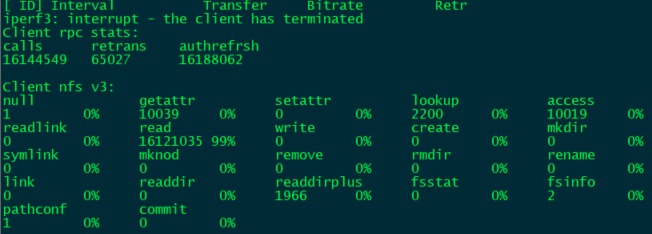
One thing I did find is that there is a significantly high number of NFS retrans on the Plex server to the NAS. I believe there is an automated plex scan running that is hammering the NFS queries and causing the issue. These numbers were only 24 hours after swapping from SMB to NFS for the mount.
Hey @ChuckPa, not sure if you remember me. I had a similar issue as Jay and made a post here about it. Jay and I have been chatting over on Reddit, where it seems others have encountered similar behavior albeit with different setups.
The one thing Jay and I had in common was our NAS was plugged into a UniFi Aggregation switch. Since I moved mine over to a new UniFi 10-Gb switch and took the Aggregation switch out of the network path, I have not encountered the issue anymore. All in all, very odd behavior. I might move my NAS back over to the Aggregation switch to see how my nfsstat’s compare between now and then.
Network setup is 10Gbps to the Synology NAS using Intel X520 with DAC to an Ubiquiti 10Gbps Aggregate Layer 2 Switch. This has a 10Gbps DAC to a core UDM Pro, from there the plex is on a different network with the L3 being on the UDM Pro and connects via 1Gbps RJ45 to a Ubiquiti Access switch. Plex itself is hosted on a Proxmox VM running Ubuntu 22.0.4 LTS. I did have Jumbo frames enabled on my network gear, but not on my NAS or Plex server, I just disabled Jumbo frames today on all network gear. This setup had been in place and working fine for about 2 years prior to this issue starting up. And one thing to note is that when this happens its only a problem between Plex and the NAS. If SMB/NFS starts failing, from another device like my PC to the same content works fine.
Yeah its not on the official list, but the drivers install automatically just fine. Its the Intel X520-T1, single port instead of the dual port X520-T2. I also reconfigured my NAS to use the onboard RJ45 interfaces at 1Gbps and the issue persisted.
One of the things im considering for a next step is that I have extra ports available on my ProxMox server and my NAS, i may try directly cabling them together over 1Gbps RJ45.
with the Syno as 1/2 the equation, have you done an iperf3 stress test on the network layer? This confirms L2 & L3 are solid. I would rub it for however long it takes to trigger the failure.
You should get some retrans in one direction but the -R direction should have none.
With Plex? Its random however it seems to happen more during the evening or when new content is added. Sometimes it will be fine for 4-5 hours, yesterday for example it was every 5 minutes, however I was trying to watch a show that I had just added. Its not file specific because some times media will play horribly, then the next time it plays just fine. It happens with 1080p or 4k being played on a 4K TV.
You turned off DEBUG which prevented me from seeing the majority of what I need
The errors I do see are inotify event queue overflow errors
Received unexpected inotify event: 1073750016
From the Wiki:
The error “Received unexpected inotify event: 1073750016” indicates that an application using the Linux inotify system received an unknown or unhandled event code. The specific value, 1073750016, is a bitmask that combines two important events: IN_Q_OVERFLOW and IN_ISDIR.
Decoding the inotify event code
IN_Q_OVERFLOW (0x00004000 or 16384): This event indicates that the event queue for the inotify instance has overflowed and some events were lost. This happens when file system changes occur faster than the monitoring application can process them.
IN_ISDIR (0x40000000 or 1073741824): This is not a standalone event but a flag that’s often combined with other events to indicate that the event occurred on a directory.
The decimal value 1073750016 is the result of adding the two hexadecimal values together: 0x40000000 + 0x00004000 = 0x40004000
In decimal, this is 1073741824 + 16384 = 1073750016.
The message therefore means an event queue overflow occurred while monitoring a directory.
Do you have a script / task which sets permissions on all your media recursively ?
The only thing this server does besides Plex is Tautuli, other than that it was just setup with basic user/group permissions to get Plex and the mounts working. No other scripts that I would have setup or ran for any purposes, very vanilla Ubuntu Server install. I can turn on debug/verbos logging if needed and try to capture better information.