Server Version#: 1.19.5.3035
Player Version#: N/A not a playback issue
Plex is hosted on UnRAID using Docker.
As of about 3-5 days ago I’ve been noticing frequent and repeated excessive resource utilization during the server maintenance window that is causing docker to OOM reap Plex’s processes.
This is happening across both of my Plex servers on different hardware (AMD & INTEL), however to reduce confusion I will just be posting info from the one server as they are practically identical in both content, setup, & configuration.
I am using the LinuxServer.io Plex docker container. Docker RAM limits are in place but they should be more than high enough for plex to never hit them in normal operation:
NOTYOFLIX has a 6GB RAM limit for Plex and I am the only user/streamer from this server.
NODEFlix has an 8GB limit set for Plex.
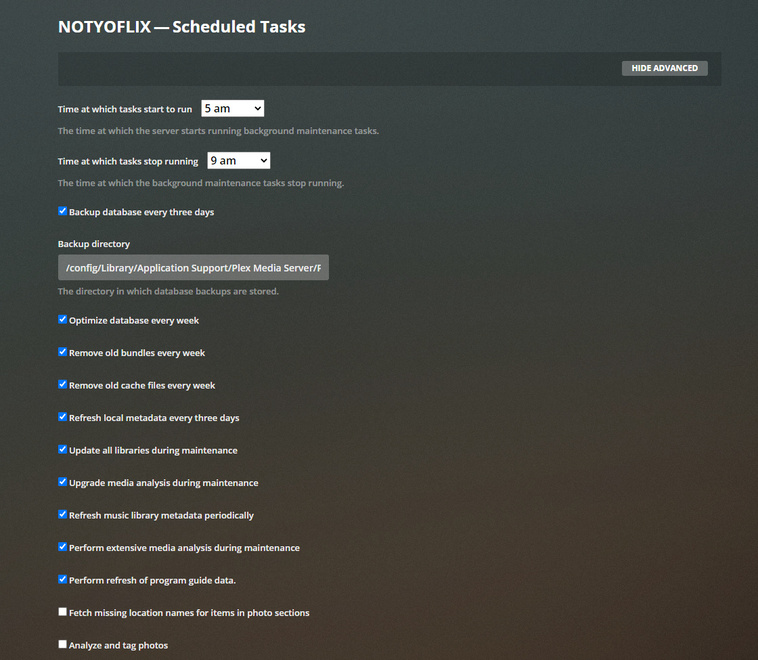
My server maintenance window is between 5AM and 9AM and like clockwork about 30 minutes into the maintenance window plex starts trying to take every bit of RAM it can get its hands on and is subsequently killed for being greedy
1. Jul 6 05:30:48 VOID kernel: CPU: 2 PID: 29776 Comm: Plex Script Hos Not tainted 4.19.107-Unraid #1
2. Jul 6 05:30:48 VOID kernel: Hardware name: Gigabyte Technology Co., Ltd. To be filled by O.E.M./970A-DS3P, BIOS FD 02/26/2016
3. Jul 6 05:30:48 VOID kernel: Call Trace:
4. Jul 6 05:30:48 VOID kernel: dump_stack+0x67/0x83
5. Jul 6 05:30:48 VOID kernel: dump_header+0x66/0x289
6. Jul 6 05:30:48 VOID kernel: oom_kill_process+0x9d/0x220
7. Jul 6 05:30:48 VOID kernel: out_of_memory+0x3b7/0x3ea
8. Jul 6 05:30:48 VOID kernel: mem_cgroup_out_of_memory+0x94/0xc8
9. Jul 6 05:30:48 VOID kernel: try_charge+0x52a/0x682
10. Jul 6 05:30:48 VOID kernel: ? __alloc_pages_nodemask+0x150/0xae1
11. Jul 6 05:30:48 VOID kernel: mem_cgroup_try_charge+0x115/0x158
12. Jul 6 05:30:48 VOID kernel: __add_to_page_cache_locked+0x73/0x184
13. Jul 6 05:30:48 VOID kernel: add_to_page_cache_lru+0x47/0xd5
14. Jul 6 05:30:48 VOID kernel: filemap_fault+0x238/0x47c
15. Jul 6 05:30:48 VOID kernel: __do_fault+0x4d/0x88
16. Jul 6 05:30:48 VOID kernel: __handle_mm_fault+0xdb5/0x11b7
17. Jul 6 05:30:48 VOID kernel: ? hrtimer_init+0x2/0x2
18. Jul 6 05:30:48 VOID kernel: handle_mm_fault+0x189/0x1e3
19. Jul 6 05:30:48 VOID kernel: __do_page_fault+0x267/0x3ff
20. Jul 6 05:30:48 VOID kernel: ? page_fault+0x8/0x30
21. Jul 6 05:30:48 VOID kernel: page_fault+0x1e/0x30
22. Jul 6 05:30:48 VOID kernel: RIP: 0033:0x149ce5010740
23. Jul 6 05:30:48 VOID kernel: Code: Bad RIP value.
24. Jul 6 05:30:48 VOID kernel: RSP: 002b:0000149cdd8ac2c8 EFLAGS: 00010207
25. Jul 6 05:30:48 VOID kernel: RAX: 0000000000000000 RBX: 0000000000000005 RCX: 0000149ce5001bb7
26. Jul 6 05:30:48 VOID kernel: RDX: 00000000000003ff RSI: 0000149cb4004d90 RDI: 0000000000000000
27. Jul 6 05:30:48 VOID kernel: RBP: 0000149cb4004d90 R08: 0000000000000000 R09: 0000000000000000
28. Jul 6 05:30:48 VOID kernel: R10: 00000000000000c8 R11: 0000000000000293 R12: 00000000000003ff
29. Jul 6 05:30:48 VOID kernel: R13: 00000000000000c8 R14: 0000149cb4004d90 R15: 0000149ce1490c30
30. Jul 6 05:30:48 VOID kernel: Task in /docker/9af320f12a9307277545efcf40eb6085d0bac2ded02eb6ce43fd8fb6f51eca33 killed as a result of limit of /docker/9af320f12a9307277545efcf40eb6085d0bac2ded02eb6ce43fd8fb6f51eca33
31. Jul 6 05:30:48 VOID kernel: memory: usage 6291456kB, limit 6291456kB, failcnt 63903251
32. Jul 6 05:30:48 VOID kernel: memory+swap: usage 6291456kB, limit 12582912kB, failcnt 0
33. Jul 6 05:30:48 VOID kernel: kmem: usage 49256kB, limit 9007199254740988kB, failcnt 0
34. Jul 6 05:30:48 VOID kernel: Memory cgroup stats for /docker/9af320f12a9307277545efcf40eb6085d0bac2ded02eb6ce43fd8fb6f51eca33: cache:6064KB rss:6236156KB rss_huge:409600KB shmem:0KB mapped_file:132KB dirty:264KB writeback:0KB swap:0KB inactive_anon:8KB active_anon:6236200KB inactive_file:3324KB active_file:748KB unevictable:0KB
35. Jul 6 05:30:48 VOID kernel: Tasks state (memory values in pages):
36. Jul 6 05:30:48 VOID kernel: [ pid ] uid tgid total_vm rss pgtables_bytes swapents oom_score_adj name
37. Jul 6 05:30:48 VOID kernel: [ 28107] 0 28107 50 1 28672 0 0 s6-svscan
38. Jul 6 05:30:48 VOID kernel: [ 28160] 0 28160 50 1 28672 0 0 s6-supervise
39. Jul 6 05:30:48 VOID kernel: [ 28978] 0 28978 50 1 28672 0 0 s6-supervise
40. Jul 6 05:30:48 VOID kernel: [ 28981] 99 28981 4021481 1367128 12034048 0 0 Plex Media Serv
41. Jul 6 05:30:48 VOID kernel: [ 29020] 99 29020 427824 15510 561152 0 0 Plex Script Hos
42. Jul 6 05:30:48 VOID kernel: [ 29173] 99 29173 108976 396 270336 0 0 Plex Tuner Serv
43. Jul 6 05:30:48 VOID kernel: [ 29628] 99 29628 220654 6237 405504 0 0 Plex Script Hos
44. Jul 6 05:30:48 VOID kernel: [ 29957] 99 29957 424266 115539 1437696 0 0 Plex Script Hos
45. Jul 6 05:30:48 VOID kernel: [ 30042] 99 30042 223846 9600 430080 0 0 Plex Script Hos
46. Jul 6 05:30:48 VOID kernel: [ 648] 99 648 4483 190 73728 0 0 EasyAudioEncode
47. Jul 6 05:30:48 VOID kernel: [ 20102] 99 20102 309055 10451 491520 0 0 Plex Script Hos
48. Jul 6 05:30:48 VOID kernel: [ 20457] 99 20457 255860 6914 442368 0 0 Plex Script Hos
49. Jul 6 05:30:48 VOID kernel: [ 20629] 99 20629 357793 8912 495616 0 0 Plex Script Hos
50. Jul 6 05:30:48 VOID kernel: [ 20838] 99 20838 223139 9579 434176 0 0 Plex Script Hos
51. Jul 6 05:30:48 VOID kernel: [ 2050] 99 2050 47443 6783 393216 0 0 Plex Transcoder
52. Jul 6 05:30:48 VOID kernel: Memory cgroup out of memory: Kill process 28981 (Plex Media Serv) score 871 or sacrifice child
53. Jul 6 05:30:48 VOID kernel: Killed process 29957 (Plex Script Hos) total-vm:1697064kB, anon-rss:462156kB, file-rss:0kB, shmem-rss:0kB
54. Jul 6 05:30:48 VOID kernel: oom_reaper: reaped process 29957 (Plex Script Hos), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB
55. Jul 6 05:30:48 VOID kernel: Plex Media Serv invoked oom-killer: gfp_mask=0x6200ca(GFP_HIGHUSER_MOVABLE), nodemask=(null), order=0, oom_score_adj=0
56. Jul 6 05:30:48 VOID kernel: Plex Media Serv cpuset=9af320f12a9307277545efcf40eb6085d0bac2ded02eb6ce43fd8fb6f51eca33 mems_allowed=0
Here is an excerpt from this morning’s syslog showing the repeated OOM reaping: https://pastebin.com/PcmbqquR
UnRAID server Diagnostics zip file: void-diagnostics-20200706-0702.zip (199.3 KB)
Plex log directory with debug enabled during crashing.
Logs.zip (5.0 MB)
I never noticed these issues until a few weeks after the detect into feature was introduced though it doesn’t seem to be explicitly caused by intro detection…
I manually initiated a rescan of all Intro’s on NOTYOFLIX in an attempt to reproduce the issue but I couldn’t, it only seems to occur during the sever maintenance window.
I have turned off intro detection and am waiting for tomorrow’s maintenance window to see if disabling that setting prevents the OOM issues.
EDIT: My docker command if that helps:
root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name=‘plex’ --net=‘host’ --cpuset-cpus=‘2,4,3,5’ -e TZ=“America/Chicago” -e HOST_OS=“Unraid” -e ‘VERSION’=‘latest’ -e ‘NVIDIA_VISIBLE_DEVICES’=‘’ -e ‘PUID’=‘99’ -e ‘PGID’=‘100’ -e ‘TCP_PORT_32400’=‘32400’ -e ‘TCP_PORT_3005’=‘3005’ -e ‘TCP_PORT_8324’=‘8324’ -e ‘TCP_PORT_32469’=‘32469’ -e ‘UDP_PORT_1900’=‘1900’ -e ‘UDP_PORT_32410’=‘32410’ -e ‘UDP_PORT_32412’=‘32412’ -e ‘UDP_PORT_32413’=‘32413’ -e ‘UDP_PORT_32414’=‘32414’ -v ‘/mnt/user’:‘/media’:‘rw’ -v ‘’:‘/transcode’:‘rw’ -v ‘/mnt/cache/appdata/plex’:‘/config’:‘rw’ --memory=6G ‘linuxserver/plex’


 So many files, so many occupied resources.
So many files, so many occupied resources.