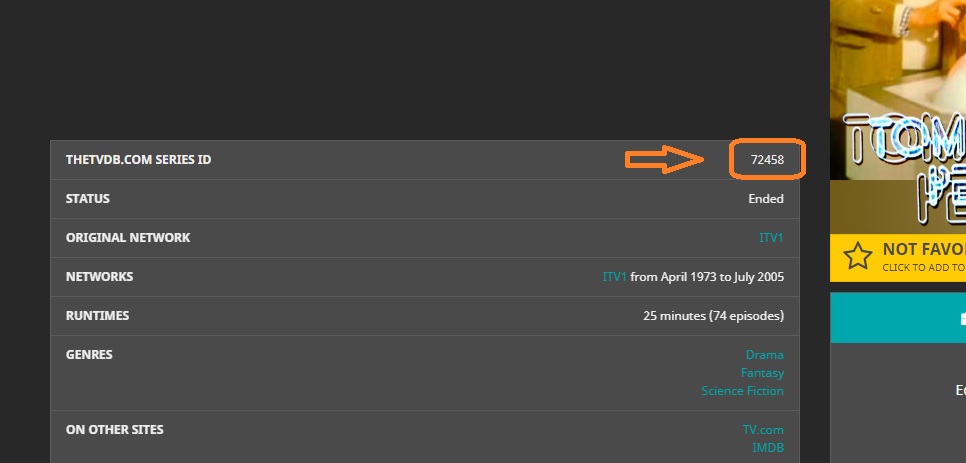
… and if all else fails - or you want instant gratification - the TVDB ID# is a bit of magic that never fails (he says with no confidence what-so-ever, but for me it works great):
just to add - you can grab that number out of the url from IMDB or TMDB and it works the same magic for movies - should one need it at some point… The IMDB # contains “tt” <—include that with the number, no such thing at TMDB, it’s just a number.
And thats the thing. I always knewyou could use the IMDB number for movies (as its documented.)
Until you mentioned it a few weeks ago I had no idea you could do it for the TVDB (maybe it’s also documented and I missed it.)
Perhaps - I was reading a thread about a mismatch and a Ninja, Employee or User mentioned it and I was instantly sold on the idea - then played with TMDB and whoosh - Happy Town.
Note: Proper naming and structuring is the key to all things, but occasionally - “Split (2017)” comes to mind - it is handy.
Also having this issue lately. It will not automatically find shows on TVDB anymore. The Movie Database works fine though. I think somethings up with Plex. It also takes FOREVER to search before returning a cannot find show. Like 5 minutes of searching.
An hour ago TVDB.com was - unavailable. Seems fine now.
Filebot, however, is still unable to negotiate a connection so TVDB’s current problems continue.
Plex will match tvdb using series ID for me but will not download any metadata. Python 2.7 is the default on my system. If this is indeed an SSL pylib issue, is there a plan to apply a hotfix in the meantime? Thanks devs!
edit: Series & episode descriptions eventually do download after a long delay but posters do not.
However, I just had a bunch go through - then they started to fail again:
2020-01-10 22:06:05,678 (7fab7c680700) : DEBUG (networking:143) - Requesting ‘https://tvdb2.plex.tv/series/295640/episodes?page=1’
2020-01-10 22:06:45,418 (7fab7cc5c700) : INFO (init:175) - Problem with the request: The read operation timed out
If I read correctly they stopped using legacy ssh/rss and will only use their new API now. That alone has messed up Filebot and I am sure it will effect Plex in some way. I would guess both scrappers used the same or close to same format.
I am able to get metadata for Plex from TVDB if I name my files (properly) by hand (the old ways are NOT the best ways), but Filebot can’t connect to TVDB at all. I am sure of nothing at this point.