Been having some unstability issues the last few days, having to reboot the whole NAS to make Plex reachable again (usually just stopping the app and starting it again works). Tried stopping the app now after it was not reachable, and noticed that the Plex process is using almost all the RAM on the NAS, see screenshots. This was after I stopped Plex, prior to reboot. Even with the Plex app stopped there are several processes eating alot of RAM
The tricky part is noticing when it happens, both Tautulli and uptimerobot fails to report downtime since Plex is still listening on 32400. Any help would be great
These are screenshots from the NAS when Plex is not responding.
New crash just a minute ago. This time the RAM usage was normal, and I could restart Plex just by stopping the app in the gui and starting it again (logs attached).
Thank you for the reply. Yes, I am running static ip (192.168.0.105), but also running alot of docker stuff on the nas, could that screw things up? Preferred network interface was set to “any”, but i tried putting it to br0 now. Would that explain the huge RAM leak in the first logs too?
Upgraded to 1.15.8 a few days ago, still crashing several times a day. Tried setting the NIC to dedicated like you suggested, that didn’t help (think it made it even worse). Tried setting it back to any, crashed again. Three crashes just today.
I have another NAS I could migrate all the container and vpn stuff to, so that this NAS only runs Plex. Would that be an idea? If you could skim through the attached logs that would be great.Plex Media Server Logs_2019-06-03_22-00-13.zip (4.7 MB)
I’ll rather see a screendump of your network settings in QNAP, and do note, that I’m about to go on a small vacation, but I’m sure @ChuckPa can assist further here
If PMS is running as the native app (not in a container or VM), the adapter to use is br0 which is also the default gateway address of the machine itself.
Yeah, thats how it runs too. (Br0 and native app). It’s so unstable I,ve had to schedule a reboot of the NAS every night at 05:00 but still I have a crash or three during the following day / night.
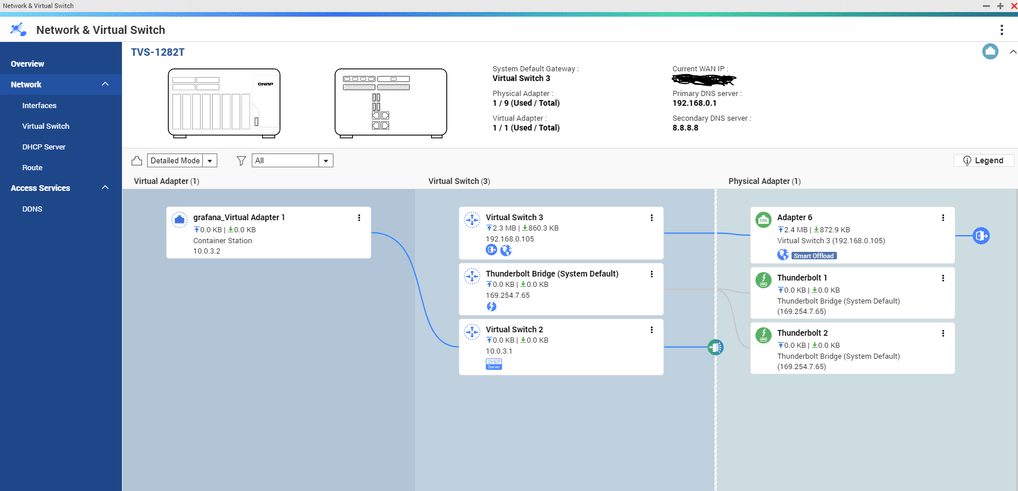
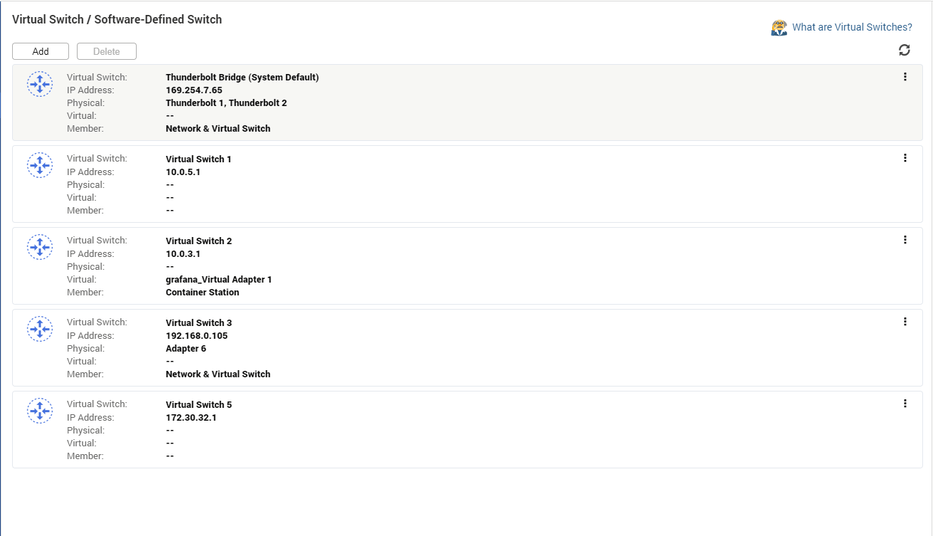
So I deleted both container station and QVPN, and installed them again after a reboot. Cleaned up the virtual switches a bit. Reinstalled Container station and I think I’m gonna move the VPN from the NAS to my router. Looks cleaner now? Also noticed that the br0 interface is gone (probably an old bridged adapter back when I had teamed two cards) and Plex is now reporting eth5.
So are you having the issue still or not post cleanup?
Another suggestion if you are still having the issue would be move your NW connection to a 1GbE port (Adapter 1) and see if that resolves the issue. I also would get rid of the auto for default gateway since you only have 1 path to your NW anyway.
It could be a weird driver glitch related to the “smart offload” function of the 10GbE card.
So far it’s looking good! A bit early to say for sure how good, but not a single crash yet.
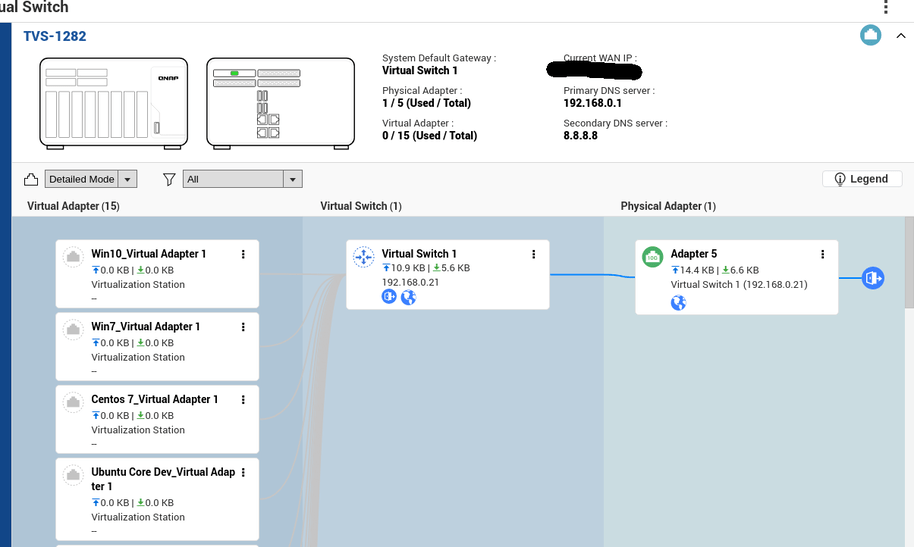
I’ll keep monitoring and post here when some more time has passed tried deleting the Thunderbolt stuff from the vswitch, not possible. 1Gbit is not a good option for me, my infrastructure is 10Gbit all over and I move a lot of data internally




 No RAM issue this time either. Had to reboot the whole NAS, stopping / starting Plex did not help.
No RAM issue this time either. Had to reboot the whole NAS, stopping / starting Plex did not help.




 tried deleting the Thunderbolt stuff from the vswitch, not possible. 1Gbit is not a good option for me, my infrastructure is 10Gbit all over and I move a lot of data internally
tried deleting the Thunderbolt stuff from the vswitch, not possible. 1Gbit is not a good option for me, my infrastructure is 10Gbit all over and I move a lot of data internally